> For the complete documentation index, see [llms.txt](https://legacy.cookielau.com/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://legacy.cookielau.com/archives/8-myblogs/5-paircoding.md).
# 2020BUAA软工——“并肩作战,平面交点Pro”
博客园链接:[Link](https://www.cnblogs.com/CookieLau/p/12560916.html)
| 项目 | 内容 |
| :----------------: | :-------------------------------------------------------------------------------------------------------------------------------: |
| 这个作业属于哪个课程 | [2020春季计算机学院软件工程(罗杰 任建)](https://edu.cnblogs.com/campus/buaa/BUAA_SE_2020_LJ) |
| 这个作业的要求在哪里 | [结对项目作业](https://edu.cnblogs.com/campus/buaa/BUAA_SE_2020_LJ/homework/10466) |
| 我在这个课程的目标是 | 完成一次完整的软件开发经历
并以博客的方式记录开发过程的心得
掌握团队协作的技巧
做出一个优秀的、持久的、具有实际意义的产品
|
| 这个作业在哪个具体方面帮助我实现目标 | 体验结对编程,两人相互配合所带来的优缺点 |
| 教学班级 | 006 |
| 项目地址 | [Intersection Pro](https://github.com/CookieLau/intersection.git) |
## PSP 规划
> 在开始实现程序之前,在下述 PSP 表格记录下你估计将在程序的各个模块的开发上耗费的时间。(0.5')
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| :------------------------------------------: | :---------------------------------: | :------: | :------: |
| **Planning** | **计划** | **15** | **10** |
| · Estimate | · 估计这个任务需要多少时间 | 15 | 10 |
| **Development** | **开发** | **780** | **965** |
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 160 |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 20 | 15 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| · Design | · 具体设计 | 60 | 80 |
| · Coding | · 具体编码 | 240 | 360 |
| · Code Review | · 代码复审 | 60 | 40 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| **Reporting** | **报告** | **80** | **80** |
| · Test Report | · 测试报告 | 30 | 30 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| | 合计 | **875** | **955** |
## 接口设计
> 看教科书和其它资料中关于 Information Hiding,Interface Design,Loose Coupling 的章节,说明你们在结对编程中是如何利用这些方法对接口进行设计的。(5')
这三个词对于北航计算机学院的同学们来说一定不陌生,在大二下学期所接触的 **面向对象设计与构造(Java实现)** 中,学习面向对象的三大特性的时候就已经屡次强调。在面向对象的作业中,我们使用的 **checkstyle——代码风格检测** 中也明确约束了同学们的设计。比如上面提到的:
`Information Hiding`——信息隐藏原则,就是面向对象的封装思想,对对象内部的属性不可见,但是提供对属性进行修改和获取的接口,我们的代码风格检测中就严格要求所有类内部属性为 `private`。\
这样做的好处一来是防止内部属性在未知或者由于疏忽被更改,二是进行了保密,对外部是黑盒,只提供服务。
`Interface Design`——接口设计,在面向过程的代码中我们很难体会到,但是在面向对象的学习中我们已经有所接触。接口设计是符合现实生活的常理的,比如Java的单继承多借口的机制,就是限定了一个类**只能是一个什么**,但是**可以做很多工作**。接口的实现(implements)使得类的功能多样且不发生高内聚的情况,也就是常说的——对扩展开放,对修改封闭。
`Loose Coupling`——解耦,在这次的作业中也明确让我们体验,实际上在学习计算机知识的过程中我们就已经接触过很多样例,比如操作系统中的Cache访存,Java面对对象中的抽象类,计算机网络中的层级结构,都是解耦的思想的实践,这些都可以总结成一句非常经典的话——**"计算机任何工程领域的问题,都可以通过增加一个中间层来解决"**。一个中间层使得两个对端不能“死”链接,降低了模块之间的耦合性。
在本次的实验中,我和我的队友通过实现前沟通修改文档的方式来实现通过接口连接核心成分和UI界面,达到的效果也令人满意,写好了内部的数据结构的操作之后只需要保证接口的正确性就可以随意调用。
## 计算接口设计实现
> 计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(7')
算法的关键和特性如下:
### 线段部分
本次作业的计算部分是对[上一次的个人作业](https://edu.cnblogs.com/campus/buaa/BUAA_SE_2020_LJ/homework/10429)中的需求的延申,虽然上一次中[我的项目](https://www.cnblogs.com/CookieLau/p/12457905.html)没有对附加题进行实现,但是已经完成的部分都是保证了严格的正确性且给这次作业的需求预留了空间。
在上一次作业中,只需要求解**直线**之间的交点,在本次作业中,加入了**线段和射线**的需求,而我再存储直线的表达式的时候,没有采用上次作业中很多同学的 **直线一般式** ,而是利用了类似于参数方程的方式,存储一段起点和线的延申方向,在求解的过程中,距离的表示也是使用的 **输入的两点的向量的倍数** 的方式,所以在本次作业中,扩展不需要改动任何代码,只需要 **对倍数进行约束即可**,具体表现为:\
1\. 对于直线而言,倍数没有任何限制,因为可以**两端无限延长**\
2\. 对于射线而言,倍数是非负数,因为可以**一端无限延长**\
3\. 对于直线而言,倍数是0到1之间的数值,因为**不能做延长**
所以线之间的相交只需要5min即可完成需求。
### 圆部分
对于上一次作业中对圆的部分没有实现,主要是在推导的时候没有给自己留下充裕的时间,导致出现了一些错误,在本次作业中我重新对圆圆相交和圆线相交进行了推到并求值,在这里感受到了**结对编程的好处**——我负责实现功能的同时,他负责盯着我的代码和构造测试数据。因为利用直线的参数方程在计算圆的相关交点需要很多中间变量,还有不可避免地做很多辅助线段,命名也不是很方便,所以在我们实现的时候,我将推导的过程讲述一遍给我的同伴,并共用一套标记,比如在我们的具体代码实现中的很多不知所云的点—— `P, M, S, Q`。当然我知道这种不知所云的编程方式,如 `CalculatePM(Circle c, Line l)` 会对其他人理解我的代码造成极大的困惑,特别是我的很多向量运算如内积,所以我在求解圆的相关内容的函数附近加上了详细的注释,保证了读一遍注释就能在草稿纸上画出一个样例,并清晰理解其中每个点对应的意义,如“垂足、距离相近的交点”等等。
### 新增和删除操作
对于新增的插入删除的需求,我和同伴达成一致,采用了 **逻辑删除** 的实现。何为逻辑删除,其实在数据库中经常用到。当删除数据库中的某一条数据,如用户数据,会对数据库中的其他表造成连带影响的时候,可以考虑将该数据的 **存在属性置为假**,也就是虽然表中有他但是实际上他不会被使用。我们之所以也选择这种方式是为了避免出现容器中的错位,由于我们直接使用`std::vector`进行存储,所以删除中间元素会给后续的元素的下标索引带来变动,需要修改多处的对应关系,而将其逻辑删除则不会造成这种负面的影响,只需要在访问元素的时候首先判断该元素是否存在`isExists?` 即可。至于我们为什么使用`std::vector`而不使用如`std::unordered_map`之类的操作,后面会说到。
### 异常处理的操作
对异常的处理可以从时间上分为两种方式:\
1\. 运行前处理(输入时处理)\
2\. 运行时处理
两者各有优劣,在这里我们使用了**运行时处理**的方式,主要理由有下:\
1\. 运行前处理存在 **误抛异常** 的风险:\
这一点是我在面向对象的课程中体会到的。我们面向对象第一单元的作业中就有异常处理的部分,和很多人一样,我当时也采用的是输入时处理的方式,只要在输入中检测到异常我就立刻抛出,结束程序。最后的程序结果也和不少同学一样,对于异常情况反应过激,很多正确的样例我们也抛出了异常。因为在输入中对异常的逻辑判断是要 **保证宁杀一千不放走一个的**,因为后面已经没有可以处理异常的部分了,再有异常就会使得程序崩溃,所以在设计上过于严格导致误判。\
2\. 运行前处理其实就是将过程中遇到的问题整合在了最前方而已:\
其实我们在输入时的处理函数,就是后续的计算函数中的一部分,比如线和线之间重合的异常,在我们的计算模块中,会线求解两个线段的向量的内积,然后将内积当作分母求值。在求内积的时候我们实际上对于平行线段就已经能进行探测了,只要两线平行且两线各取一点的连线还与两线平行就是重合的情况,这种异常情况在我们判断分母是否为0的时候就已经接触,而且是一个必要的过程,所以放到前面实际上是代码的冗余了。\
3\. 计算交点是一个 **“一次性运行”** 的计算过程:\
给定一份输入,经过 **“一次性运行”** 给出一个输出结果,是一个“不可迭代”的过程。什么意思呢?这个带上双引号的 “不可迭代” 指的是对于新增线段的需求和删除线段的需求是不可迭代的,不是说减少一个图形就是在当前结果的基础上进行减少,而是将减少之后的整理重新进行一遍从头的计算。因为对于交点而言处理删除比重新运行更加繁琐,你不知道删除之后在删除图形上的交点是否也是其他图形之间的交点,实际上计算量是一样的。所以对于这种 **“一次性运行”** 的计算过程,从在输入时刻抛出异常而节省的时间我认为是不必要的,因为单次运行的时间是可接受的(测试中用了2000个图形的数据在10s左右给出答案,和课程组预设的60s相比时间宽裕)
### 代码组织架构
使用了非常常规的代码组织,核心模块在 `Intersection` 文件夹中,命令行界面程序在 `IntersectionCLI` 中,图形化界面程序在 `IntersectionGUI` 中:
* Intersection
* Intersection.h
* Intersection.cpp 输入输出和计算交点的处理
* Shape.cpp 图形相关的计算
* IntersectionCLI
* main.cpp
* IntersectionGUI
* IntersectionGUI.h
* ShowPic.h
* IntersectionGUI.ui
* IntersectionGUI.cpp 掌控布局和链接
* main.cpp
* ShowPic.cpp 绘制图像
* CoverageTest
* coverageTest.cpp 覆盖测试文件夹
* Test
* intersectTest.cpp 交点的单元测试回归测试
* errorHandleTest.cpp 错误处理的单元测试回归测试
* ShapeTest.cpp 图形相关的单元测试回归测试
## UML设计
> 阅读[有关 UML 的内容](https://en.wikipedia.org/wiki/Unified_Modeling_Language)。画出 UML 图显示计算模块部分各个实体之间的关系(画一个图即可)。(2’)
\
确实在耦合方面做的不够好,将图形都用struct保存而不是class保存所以直接放置在了Intersection.h中,其实为了后续的图形的多样性的可扩展性,应该单独出来一个Shape.h类,里面专门存放各种图形的定义,但是考虑到其实增加图形之后也要增加图形之间的交点情况,而且求解的交点的种类个数是线性增长的,所以分离出来之后感觉定义上会方便一些,但是很多求解的操作还是要在Intersection.h中,所以干脆就没有分离了。\

## 计算性能分析
> 计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2015/2017的性能分析工具自动生成),并展示你程序中消耗最大的函数。(3')
采用的样本是 **1000个圆和2000条线**:\
\

可以看出还是dcmp最大占比,因为是最基础的比较函数,在上次的个人作业结束后曾思考是否可以将两两比较的结果进行保存,但是访存的时间和直接相减计算相似,所以没有进行dcmp的优化。
## 契约式编程
> 看 Design by Contract,Code Contract 的内容: 描述这些做法的优缺点,说明你是如何把它们融入结对作业中的。(5')
契约式编程(Design by Contract)其实在面向对象中又以及接触过,在第三单元的JML(Java Modeling Language)的学习中,就是通过学习一种特殊的Java模型语言,对输入和输出和不变量进行约束,保证任意方法能够得到想要的结果且不产生副作用,但是由于JML的配置极为麻烦,到目前为止我们只尝试过特别简单的 `a+b` 类型的JML的实际运行,但是学习这种契约式编程从理论上让我们体会到了契约的优越性和便利:只要有方法的契约,不需要知道方法的作用是什么,实际意义是什么就可以写出能够正确运行的代码。\
当然这种类似于JML的严格的契约式编程也有自身的缺点,那就是消耗成本过高——方法需要先用契约写一遍,再用高级程序设计语言翻译一遍,对于团队开发而言时间成本和人力成本是不可忽略的,这也是JML这种专门为Java设计的模型语言没有流行起来的重要原因之一,还是在理论层面更加重要。
在本次的结对编程中,我和同伴没有按照JML类似的死板的契约式编程,因为一开始负责的模块划分比较清晰,我负责核心代码,他负责GUI,所以只交流了接口的调用的函数,还有增加删除图形的功能的函数,因为项目比较小所以没有牵扯到副作用,团队规模也小,就没有进行书面的整理。
## 单元测试
> 计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。要求总体覆盖率到 90% 以上,否则单元测试部分视作无效。(6')
本次得测试分为覆盖测试和单元测试:
### 单元测试已经回归测试
我们分了三个部分进行测试:
* intersectTest.cpp 交点的单元测试回归测试
* errorHandleTest.cpp 错误处理的单元测试回归测试
* ShapeTest.cpp 图形相关的单元测试回归测试
结果如下:\

### 覆盖测试
虽然我们运行得直接输出结果没有达到90%,但是点入文件会发现其实已经做到种类的全覆盖,没有运行的部分是提供给GUI的接口,如获取所有线段和交点,还有就是调试中开发者使用的辅助函数,如:`printAllPoints()` 等

## 异常处理
> 计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(5')
异常处理包括以下几个部分:\
1\. 线之间的重叠(这里要特别考虑相交于一点不是重叠的情况)
```
input.txt
2
L 1 1 2 2
L -1 -1 0 0
```
```cpp
TEST_METHOD(LL_0)
{
try {
ifstream in("../test/errortestcase/5.txt");
Intersection* intersect = new Intersection();
intersect->getAllPoints(in);
intersect->solveIntersection();
Assert::IsTrue(false);
}
catch (string msg) {
Assert::AreEqual(string("直线与直线或线段重合"), msg);
}
}
```
1. 线的两端点重合
```
input.txt
1
L 1 2 1 2
```
```cpp
TEST_METHOD(INPUT_1)
{
try {
ifstream in("../test/errortestcase/1.txt");
Intersection* intersect = new Intersection();
intersect->getAllPoints(in);
Assert::IsTrue(false);
}
catch (string msg) {
Assert::AreEqual(string("在第1行,构成线段、射线或直线的两点重合"), msg);
}
}
```
2. 圆圆重合
```
input.txt
4
C 0 0 5
L 1 0 0 1
S 2 4 6 8
C 0 0 5
```
```cpp
try {
ifstream in49("../test/errortestcase/26.txt");
intersect->getAllPoints(in49);
ret = intersect->solveIntersection();
assertEqual(true, false);
}
catch (string msg) {
assertEqual(string("圆和圆重合"), msg);
}
intersect->clearGraph();
```
3. 圆半径非正数
```
input.txt
2
L 0 1 1 2
C 0 10 -1
```
```cpp
if (type == 'C') {
if (!(isInLimitation(x1) && isInLimitation(y1) && isInLimitation(x2))) {
throw "出现超范围的数据";
}
if (dcmp(x2) <= 0) {
throw "圆的半径应大于0";
}
circles.push_back(Circle(Heart(x1, y1, type), x2));
}
```
4. 输入类型不正确
```
input.txt:
2
L 1 1 1 0
P 1 2 3 4
```
```cpp
TEST_METHOD(INPUT_0)
{
try {
ifstream in("../test/errortestcase/0.txt");
Intersection* intersect = new Intersection();
intersect->getAllPoints(in);
Assert::IsTrue(false);
}
catch (string msg) {
Assert::AreEqual(string("在第2行,出现未识别符号"), msg);
}
}
```
5. 输入非法字符
```
input.txt
2
L 1 abc 1 1000
C 1 1 2
```
```cpp
TEST_METHOD(INPUT_3)
{
try {
ifstream in("../test/errortestcase/3.txt");
Intersection* intersect = new Intersection();
intersect->getAllPoints(in);
Assert::IsTrue(false);
}
catch (string msg) {
Assert::AreEqual(string("在第1行,出现值错误,无法读入"), msg);
}
}
```
6. 输入参数超过给定定义域
```
input.txt
1
L 1 1 1 1000000
```
```cpp
TEST_METHOD(INPUT_2)
{
try {
ifstream in("../test/errortestcase/2.txt");
Intersection* intersect = new Intersection();
intersect->getAllPoints(in);
Assert::IsTrue(false);
}
catch (string msg) {
Assert::AreEqual(string("在第1行,出现超范围的数据"), msg);
}
}
```
## UI设计思路
> 界面模块的详细设计过程。在博客中详细介绍界面模块是如何设计的,并写一些必要的代码说明解释实现过程。(5')
在UI的设计中,我们主要是以功能为导向设计,需要的功能有:\
1\. 查看图形分布和交点——平板显示\
2\. 查看当前在面板上的图形——侧边栏展示\
3\. 查看当前的所有交点——侧边栏展示\
4\. 增加新图形的操作——按钮\
5\. 删减当前图形的操作——按钮\
6\. 打开文件的操作——按钮
辅助功能(不是必要的但是存在方便用户):\
1\. 鼠标滚轮实现缩放\
2\. 上下左右移动画布
于是一个UI就设计出来了:\

当打开图像文件时:\
\

本次的UI是基于[Qt](https://www.baidu.com/link?url=Rw6srFITx3EaAj0GjRkxNPKq18gML_H1M9NebbYPW5q\&wd=\&eqid=c1cf84790007c0e8000000065e79f38d)开发的,基本上是Cpp的语法,比较容易上手,只是Qt的组件管理比较让人头晕,主要使用了如下几个部件:\
1\. QWidget —— 显示图像的画布,重写了 QPaintEvent方法,才使得可以在上面用 QPaint 进行图像的绘制:\
1\. 初始化画笔\
 2. 绘制坐标轴\
\
3\. 绘制图形和交点\

1. 侧边的图形限制栏和交点显示栏使用的是 QListWidget,存储字符串数组并显示出来:
1. 存储图形:

2. 存储交点:
```cpp
void IntersectionGUI::getResult(void) {
int res = intersection->solveIntersection();
ui.pointNumResult->setText(QString("Answer:%1").arg(res));
vector inters = intersection->getIntersects();
ui.allIntersects->clear();
for (auto p : inters) {
ui.allIntersects->addItem(QString("(%1,%2)").arg(p.x).arg(p.y));
}
}
```
2. 按钮使用的是 QButton ,监控鼠标在上面的点击:
可以看到通过Qt自身的connect方法将UI上的Qbutton与核心函数中的槽函数连接了起来,一旦按钮被监测到点击动作就会执行槽中的函数。
```cpp
connect(ui.openFileButton, SIGNAL(clicked()), this, SLOT(openFile()));
connect(ui.getResult, SIGNAL(clicked()), this, SLOT(getResult()));
connect(ui.deleteShape, SIGNAL(clicked()), this, SLOT(deleteItem()));
connect(ui.zoom_in, SIGNAL(clicked()), this, SLOT(zoom_in()));
connect(ui.zoom_out, SIGNAL(clicked()), this, SLOT(zoom_out()));
connect(ui.addItem, SIGNAL(clicked()), this, SLOT(addItem()));
connect(ui.zoom_reset, SIGNAL(clicked()), this, SLOT(zoom_reset()));
connect(ui.left, SIGNAL(clicked()), this, SLOT(moveLeft()));
connect(ui.right, SIGNAL(clicked()), this, SLOT(moveRight()));
connect(ui.up, SIGNAL(clicked()), this, SLOT(moveUp()));
connect(ui.down, SIGNAL(clicked()), this, SLOT(moveDown()));
```
3. 画布的轮滑放缩:\
实际上就是监控鼠标的位置并且重写鼠标的滚轮滚动时的对应函数:
```cpp
void IntersectionGUI::wheelEvent(QWheelEvent *event)
{
QPoint pos;
QPoint pos1;
QPoint pos2;
pos1 = mapToGlobal(QPoint(0,0));
pos2 = event->globalPos();
pos = pos2 - pos1;
//判断鼠标位置是否在图像显示区域
if (pos.x() > showPic->x() && pos.x() < showPic->x()+showPic->width()
&& pos.y() > showPic->y() && pos.y() < showPic->y()+showPic->height())
{
// 当滚轮远离使用者时进行放大,当滚轮向使用者方向旋转时进行缩小
if(event->delta() > 0)
{
zoom_in();
}
else
{
zoom_out();
}
}
}
```
## UI功能展示
> 界面模块与计算模块的对接。详细地描述 UI 模块的设计与两个模块的对接,并在博客中截图实现的功能。(4')
1. 打开文件:
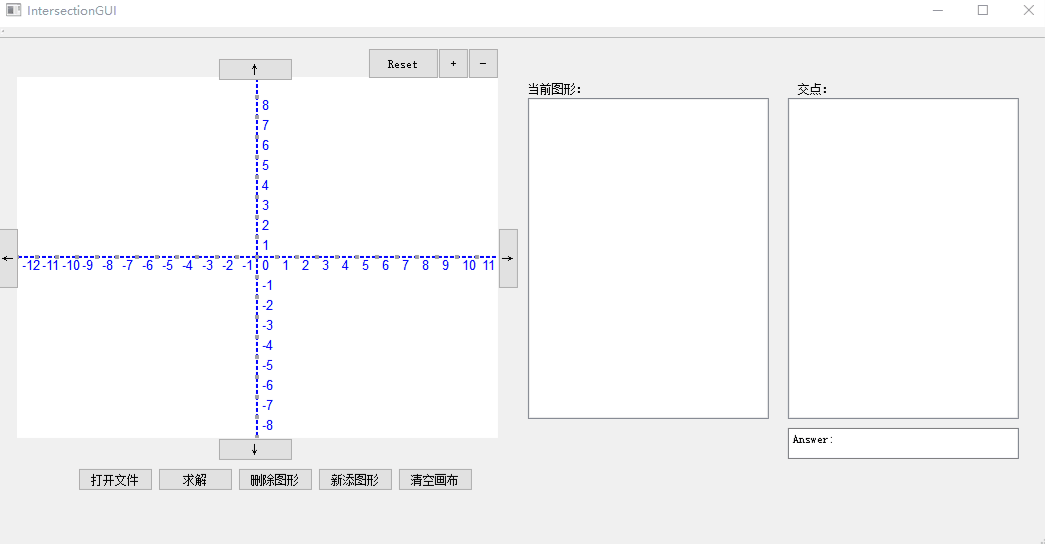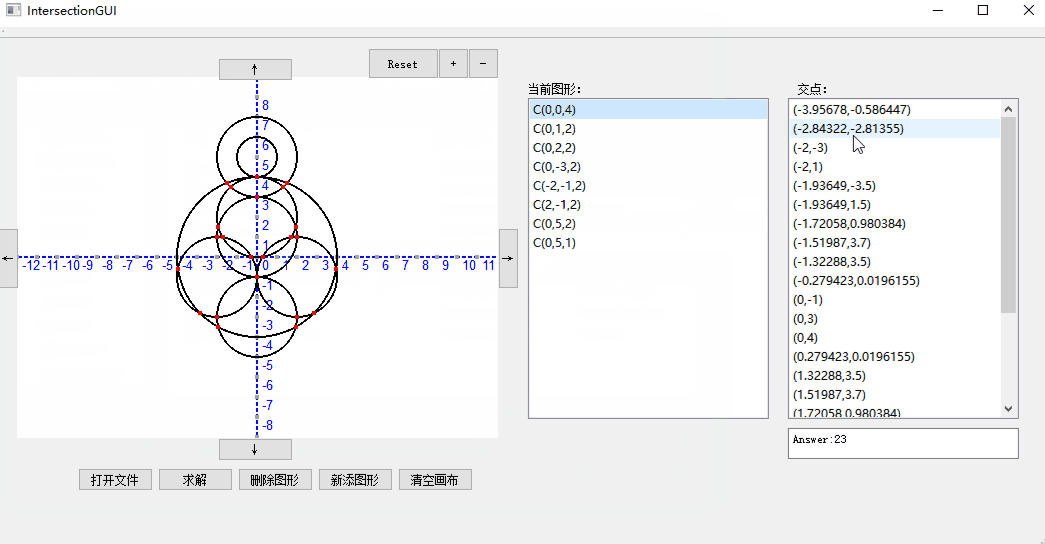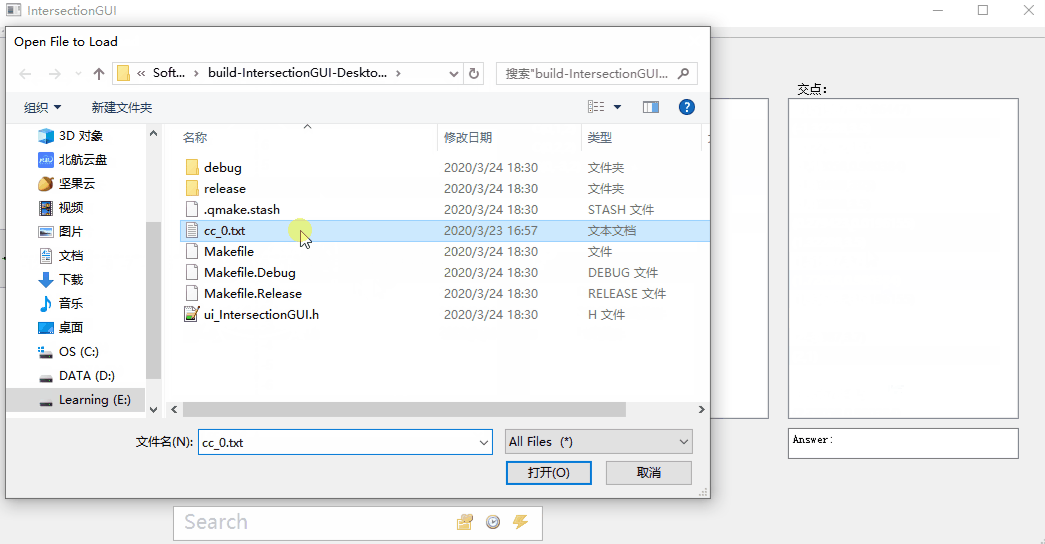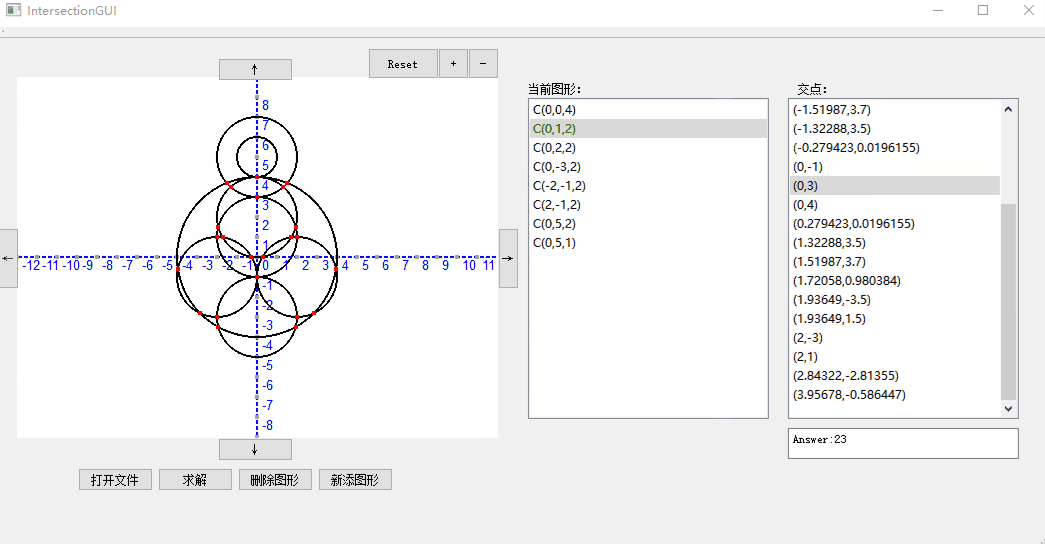
2. 增加删除元素:
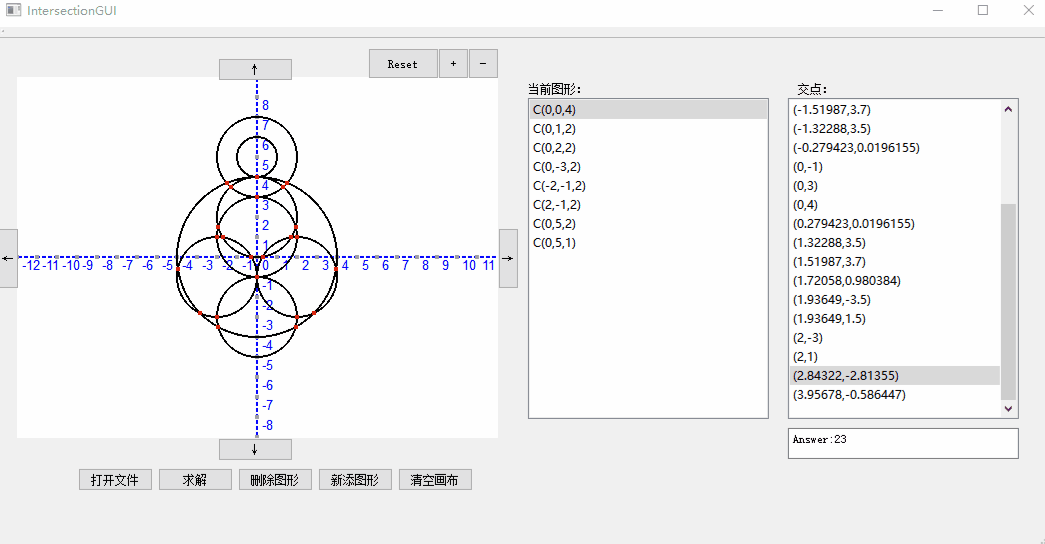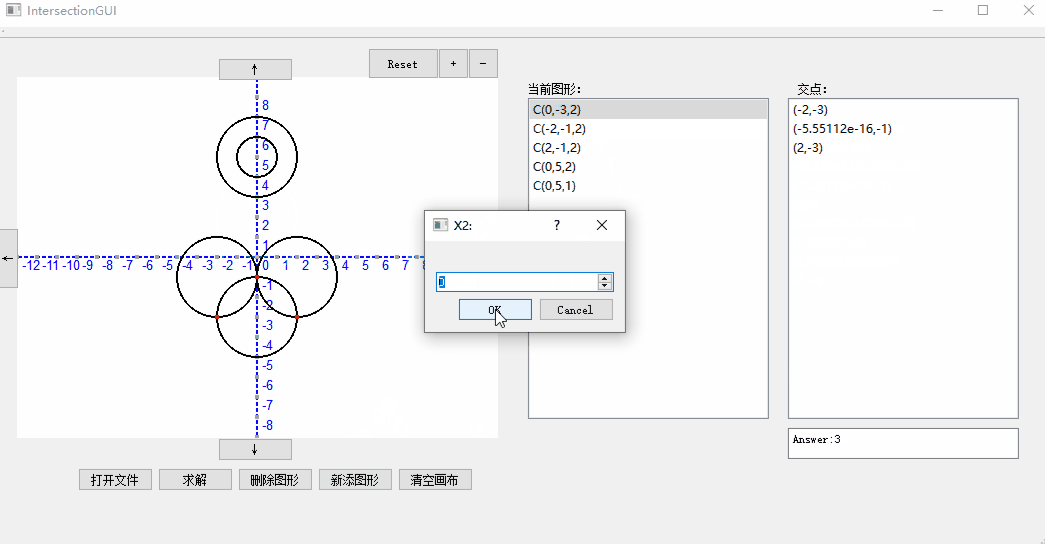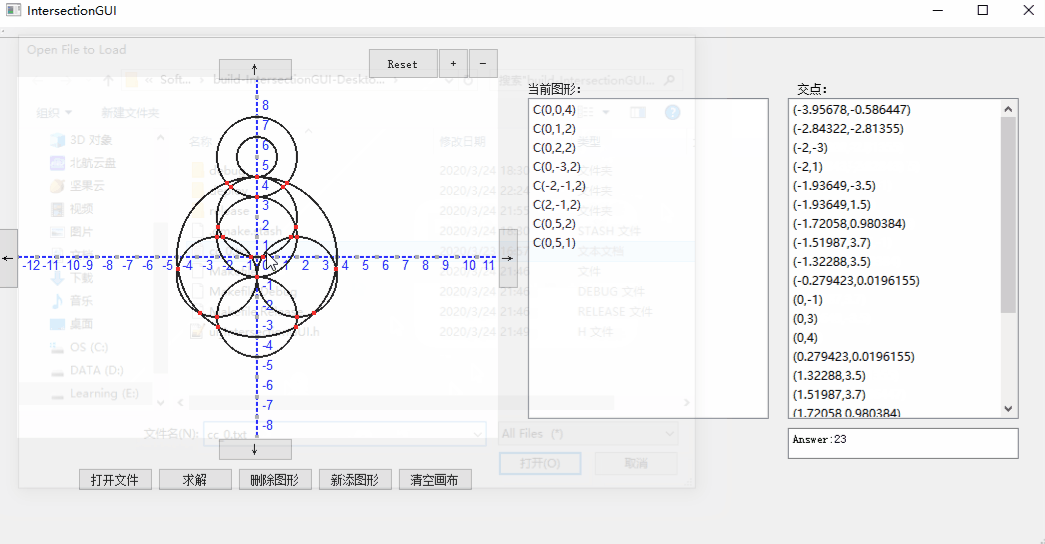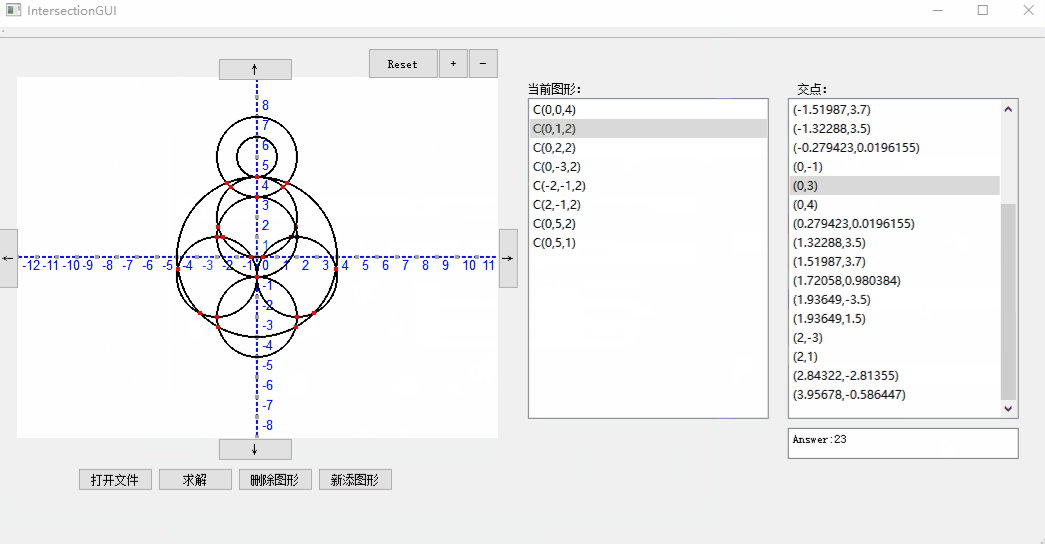
3. 鼠标滚轮放大缩小与移动:
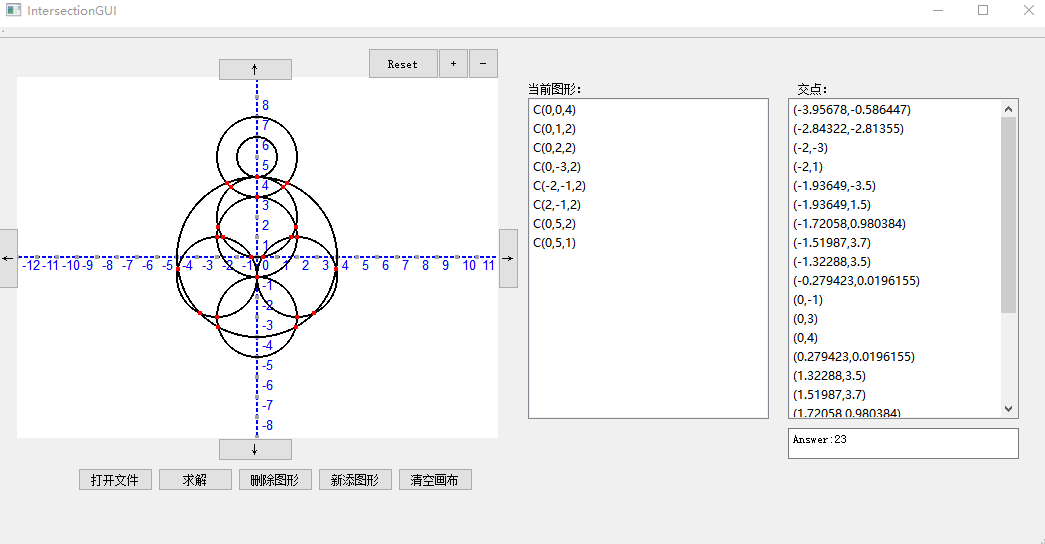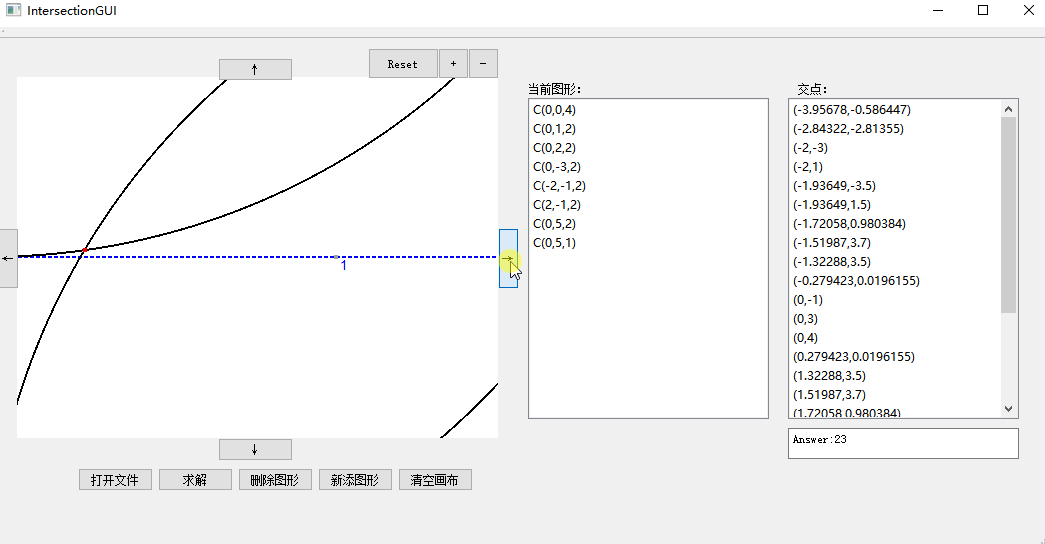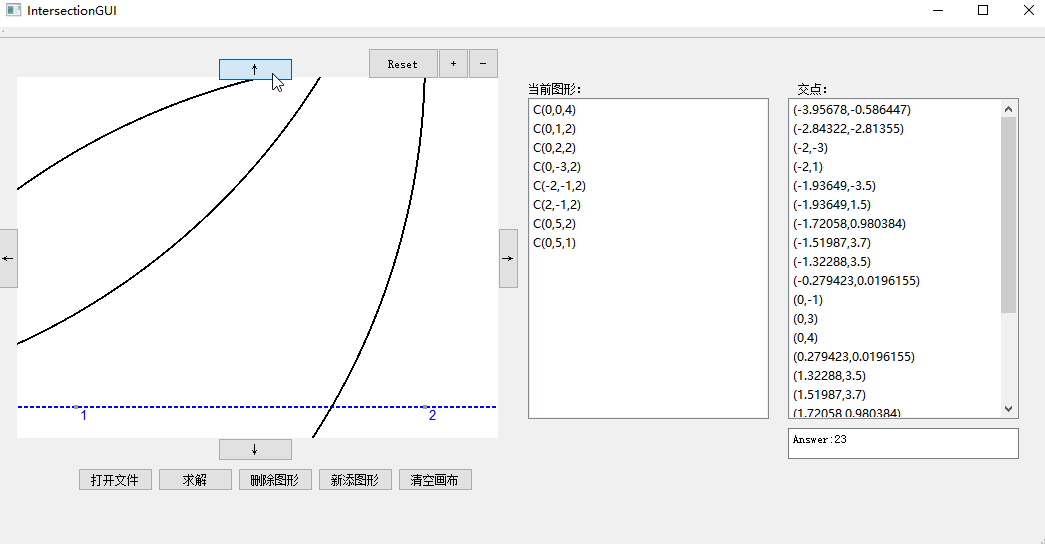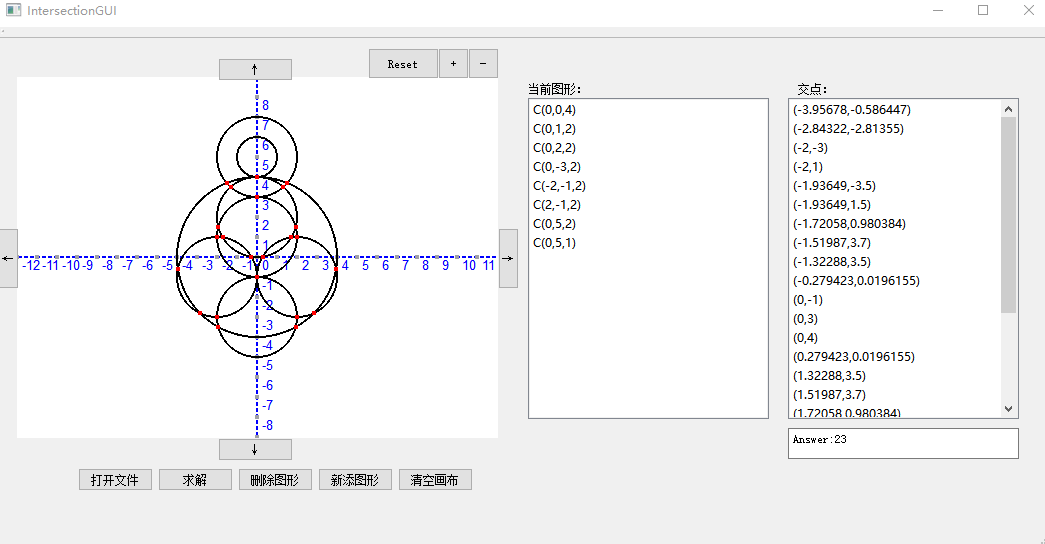
## 结对现场展示
> 描述结对的过程,提供两人在讨论的结对图像资料(比如 Live Share 的截图)。关于如何远程进行结对参见作业最后的注意事项。(1')
由于疫情原因这学期的结对编程未能在同地编程,所以采用了远程的方式,我们采取的具体方案是LiveShare + 微信语音通话的方式进行,下面是LiveShare的截图:\

## 结对编程优缺点
> 看教科书和其它参考书,网站中关于结对编程的章节,例如:[现代软件工程讲义 3 结对编程和两人合作](http://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html) ,说明结对编程的优点和缺点。同时描述结对的每一个人的优点和缺点在哪里(要列出至少三个优点和一个缺点)。(5')
体验过这一次的结对编程之后,我算是亲身体会到了[邹欣老师博客](http://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html)中所说的结对编程中的角色。\
这和大型交通工具都配有副驾驶的思想大抵是一致的,当一个人长时间驾驶产生疲劳之后,需要副驾驶来交替;当驾驶员在驾驶的时候,副驾驶员不是无所事事的,是辅助驾驶员正确行驶的,在以往这种辅助驾驶主要体现在领航和提醒的作用上,现在由于电子地图的兴起,副驾驶更多的是提供临时的帮助和关键时刻的决定。\
我和我的同伴在结对编程的时候,一开始是我专门负责核心框架,他负责帮我测试和写界面UI,经过第一轮实现所有需求之后,他构造出来的样例确实能把我的很多细节的地方揪出来,这就是结对编程的第一第二个优点:\
1\. **并行完成任务——高效。**\
2\. **看问题更加全面,弥补一个人容易疏忽的细节。**
后来,开始到了UI的链接和异常处理的部分,我们两人则尝试着交换身份,我来着手UI,他来编写异常处理,这是结对编程的第三个好处:
1. **两人都可以接触到UI和核心模块的开发,轮替开发不会有严重的疲劳感。**
一直对着同一项工作特别容易产生疲劳,而这种疲劳所带来的副作用还在于对项目的“自以为是”的了解,这里的“自以为是”不是贬义词,指的是重复进行同一项劳动而产生的焦躁的不安情绪。我开发完核心模块和重构部分代码之后真的对这个项目已经有点累了,因为实际上完成了所有的需求之后就不想再进行开发了——有一种好不容易修修补补之后“能跑就行”的侥幸心理,而我的同伴在UI的部分也恰好遇到了一些状况,所以我们**一拍即合互换身份**。
最后,也是同样重要的一点,**结对编程的过程其实是共享知识的过程**。我们一定可以从对方的身上学到优点——三人行必有我师焉,我从我的结对同伴处学习到了项目的代码重构的方式,我之前是比较惧怕重构的,特别是多一点的文件,还有Visual Studio这种重量级的项目管理器,我平时比较喜欢用linux下面的命令行,编译运行什么的都是用命令行。但是在这次的实践中,我的同伴重构了两次项目,让我学习到了重构时候函数的提取,接口的抽象,如何生成DLL动态链接库使用等等,也让我没有那么惧怕Visual Studio了。
当然,结对编程也有令人不舒服的地方,每个人有自己的独特的代码风格,比如在异常处理的时候我就特别喜欢输出调试,加很多的宏定义或者辅助函数去定位错误,包括利用-1的返回值代表发生错误,而我的同伴特别喜欢抛出异常来定位,这种代码风格的不同造成了我们的代码有些不一致,体现在单元测试中有几个部分是-1,有几个部分是`try{}catch{}` 块,当然后来进行了一次统一。这里只是举了一个例子,在这次的项目中规模很小,而且UI的部分和core的部分分离的比较清楚,所以并没有发现其他的太多的出入,当然以后工作中,一个良好的团队一定会指定一个编码规范的,比如Google的代码风格和Ali的代码风格等等,人总是要约束自己一点才能和团队处得更加融洽,哈哈。
## PSP 反填
> 在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块上实际花费的时间。(0.5')
见开头的PSP表格。
这两周都花了大部分时间扑在了这个项目的实现上,其实真正编码的时间并不多,更多的时间在于 **Debug、学习UI和测试异常处理**。有一些细节性的bug真的是结对编程能立刻发现,但是自己在做的时候就是成了盲点。我和我的同伴都有遇到自己感觉很奇怪的为什么会出现bug的地方沉思许久,然后一拿给对方看就发现了某个变量的端倪,改了就跑通了的地方,也再次用 **时间的教训** 感受到了结对编程和CodeReview的好处。 此外还有很多的时间花费在了捯饬Visual Studio上面,但是对于这个大家伙的情感,从一开始完全不懂导致出现满屏的红色警告,点什么都跑不动,到每天都在查Error,查Warning,似乎每天都在查同一个链接失败的错误,找不到的错误,未定义的错误等等,用的愈发熟练,到结对项目结束的时候,以及能流畅的进行构建、清理、生成动态链接库等等,**强大的工具一定要规范地使用才能事半功倍**。
还有就是血与泪的教训:**同伴之间的工具版本最好一样!**\
因为Qt的版本不同和VS的版本不同的原因消耗了太多无用的时间,就比如说VS2017和VS2019的指令集分别是V141和V142,导致一开始怎么也无法编译,而且改了正确的版本还是无法编译的情况,既消磨时间又消磨精力,要是两人的工具集从一开始就一致必然节省很多时间。
## 完成结对项目的总结和反思
个人经历所学习到的东西:
### 版本控制
在本次的结对编程中,中途出现了一点小插曲,由于和同伴同时开发没有处理好两人的commit关系,中途贪图方便使用微信传输了一些文件和压缩包导致commit出现了混乱,加上本次项目是基于自己的上一次项目上开发,在编写 `.gitignore` 的时候不小心将 `.vs` 也加入到了`commit`中,出现了 `.git` 目录庞大的局面,导致后期两人的代码难以通过 `git` 进行协同工作,最终是感谢 LZB 同学提供的思路将提交历史中的大文件得以删除才回归正常的大小,在此也贴出来分享给大家:
* [git不小心加入了大文件如何删除](https://stackoverflow.com/questions/2100907/how-to-remove-delete-a-large-file-from-commit-history-in-git-repository)
* [直接获得一个优秀的 .gitignote](https://www.gitignore.io/)
如果觉得自己的源代码管理和版本控制做的不错的,可以参考走心老师的[现代软件工程讲义 源代码管理](https://www.cnblogs.com/xinz/p/5044037.html)章节中的连环小问题自测,我被一连串问题问得“哑口无言”,只能默默看评论区中的链接。
### "永远"不要相信任何人
这个其实是我在做单元测试的时候遇到的一个问题,思考了一下。在单元测试中我创建了一个 `intersection` 类,去读取文件计算交点得到结果等等,然后每次读完一个文件之后清空里面存储的线和圆,再去读下一个。因为我们设计的测试文件比较多,大概40多个,然后测试的时候其中有一个地方一直过不去,那一个样本本来应该交点是0个,但返回的值里面硬生生给了2个,百思不得其解,断点之后才发现是上一个测试用例读取之后没有清空,然后这次读取就累加在上面了。\
本来每个测试样例后面都应该有个 `clearGraph()` 的操作:
```cpp
ifstream in3("../test/testcase/rsc_0.txt");
intersect->getAllPoints(in3);
ret = intersect->solveIntersection();
assertEqual(ret, 11);
intersect->clearGraph(); //******************
```
但是恰巧那一个地方就漏掉了,然后就导致了单元测试不通过,于是我就在想,这个 `clearGraph()` 的操作,是不是放在读取文件前更好?如下面:
```cpp
ifstream in3("../test/testcase/rsc_0.txt");
intersect->clearGraph(); //******************
intersect->getAllPoints(in3);
ret = intersect->solveIntersection();
assertEqual(ret, 11);
```
因为放在执行完求解后面,就是一个**收尾的工作**,收尾的动作通常是是 **可有可无**(不会造成严重后果),比如很多人 `FILE*` 打开之后没有 `fclose()`,这种收尾当然有的话更加规范,但是没有的话对本单元的测试任务也不影响,**但是对后面的任务可能会带来潜在的危害**,所以我们应该将清空画板这一步放在 **读入的前面**,也就是真正开始该单元测试的最前方,我将其称之为 **“相信自己”**,自己去检查一遍、复核一遍画板是清空的,而不是 **指望别人**——在执行完单元测试之后将画板复原。
### UI比想象中的要麻烦
一开始我们在纠结是C#还是Qt进行UI的开发,因为觉得Qt和Cpp是同类型的产品应该更好上手从而选择了Qt,我的同伴没有接触过Qt,我只运行过别人写的Qt所以都比较陌生,但因为 **听说** Qt 和Cpp比较相似就没有太放在心上,结果真正到了UI开发的时候发现并没有想象的那么简单,还是花了我们不少时间去理解Qt中的组件,以及组件之间的关系,UI的组件是如何布局、是如何链接后面的函数的等等,一开始的时候就发现UI面板上零件夺得吓人,到后来入门基础知识了解概念,再到要实现什么功能去查询适合的工具,原本以为不难的UI让我们产生了焦虑,因为即使简单,你也不知道自己实现一个功能需要什么,而且Qt上的一种功能,网上可以搜索到好几种实现,也无法比较优劣,万一踩坑也只能重头开始。这对于我的启发是**在后续的团队项目中,不能忽视UI的设计和开发**。
## 参考链接
1. [stackoverflow | 如何删除git中加入的大文件](https://stackoverflow.com/questions/2100907/how-to-remove-delete-a-large-file-from-commit-history-in-git-repository)
2. [gitignore 模板大全](https://www.gitignore.io/)
3. [现代软件工程讲义 源代码管理](https://www.cnblogs.com/xinz/p/5044037.html)
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://legacy.cookielau.com/archives/8-myblogs/5-paircoding.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.